
深入 MIT 6.824:实现 LeaseRead 和全异步 shardkv
「生活,就是当你忙着做其它计划时,发生在你身上的事」:要问起开始学 MIT6.824 的缘由,这是一句恰如其分的描述。一个学期结束,原本的计划是深入研究一下编程语言和形式化验证,然后换到一个和操作系统关系更大的岗位;不知不觉却变成了写个数据库,在做操作系统相关的工作前先试试存储的方向——刚放假时我还对自己说,我是绝对不会喜欢上存储的。也许人们对自己还没下过苦功的事情,就是提不起劲的吧?
于是春节假期开始,明显一年比一年淡漠的气氛(今年甚至没看拜年祭)环绕,倒也是为思考提供了较好的场所:没有多少亲戚前来拜访,也就没有多少生硬蹩脚的玩笑和紧张尴尬的时刻需要消化。到现在,整一个月,算是把 MIT6.824 彻底完成了。
老实说,这并不如我想象中的难。在上手之前总觉得 824 的高不可攀,非顶尖学府的高手不可;但在自己突然完成之后却发现虽然过程并不是「出乎意料地」顺利,但产出确实是出乎意料地好。
我已开源了这份实现。这一实现稳定通过了 Lab 1 到 Lab 4 的每一个测试点(至少 1000 次,通常 2000 次;其中 Linearizability2B 通过了 10000 次——这么做是因为在提出 porcupine 的文章中,作者说TA “没有找到任何一个线性一致性测试不能发现的错误”),完成了 Lab 4 的两个 Challenges(即标题中的全异步 shardkv),同时还额外实现了 LeaseRead with noop 的优化,使得读请求无需经共识层——本文中提出的解决方案或许是对如何在 MIT 6.824 中实现这一优化的较好参考。另一方面,我谨慎地组织了代码结构,保证代码的粒度适宜——既不引入过多重复,又不引入过多函数(是不是想起了洗试管的原则?嘿嘿),每一次修改都执行了充分的回归测试,并且非常谨慎地操作 squash 和 cherry-pick,保证修改最少、最必要,且和我完成 Lab 的进度严格对应:这意味着读者可以从代码的提交历史中明确看到某个 Lab 和下一个 Lab 之间应要做哪些修改。
你可以从以
-test结尾的测试分支中看到是多么令人沮丧的 debug 过程被隐藏在了 cp & squash 的表象之下:
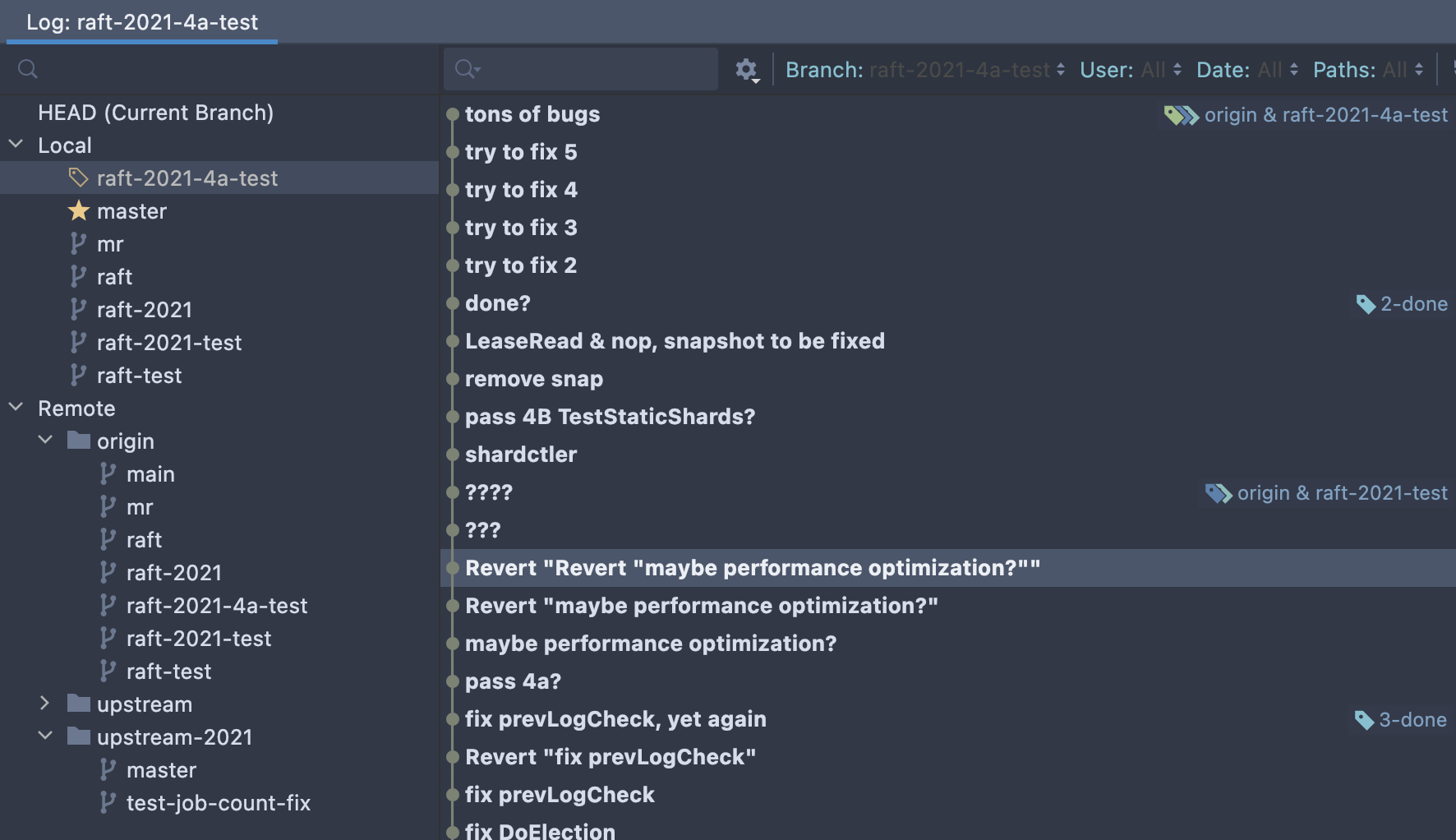
总体 Lab 的难度大概是 Lab 4B Challenges > Lab 4B > Lab 2 (2C = 2B > 2A > 2D) >> Lab 4A = Lab 3 = Lab 1。
本文将分两个部分,拆解实现中两个较为新颖的侧面:一个是(正如我刚刚提到的)全异步的 shardkv(即 Lab 4 Challenges),另一个是如何实现 LeaseRead with noop 使得读请求无需过共识层(若有机会,本博客兴许会更新完整的实现笔记,而不仅仅是两个较为新颖的侧面)。为不影响各位读者的学习体验,本文将尽可能以「问题情形——解决方法」的形式组织,当你发现无法通过的测试时,你可以阅读一节「问题情形」,在继续阅读「解决方法」之前,你应自行排查自己的实现是否足以排除了这些情形,随后你可以对照相比本文中提出的解决方法而言,你的解决方法有什么不同。
最后,显然的一点是,没有分布式和存储领域的前辈们慷慨无私地分享自己完成这一课程的宝贵经验,这篇文章不可能诞生。特别需要感谢 OneSizeFitsQuorum 的一系列讲解,尽管本文使用的方案与之迥异,却也殊途同归。其它对本文作者很有帮助的参考资料亦附在文末,推荐各位读者前往阅读。本文作者对本文的所有疏漏负全部责任。若有任何问题、讨论(比如,你的解决方法很可能比我的更好,我非常希望你能在评论区告诉我)或建议,欢迎在评论区留言。
写在前面
或许这段话并不合适出现在一篇标榜为(实际上不一定符合)「深入」的文章中,但还是必须指出几点非常重要的 rules of thumb:
- 在你启程之前,请确保你已非常认真仔细地阅读了 MIT 6.824 的所有文字指南,包括 locking guide、structure guide 和 student guide;
- 官方 guidance 中给的日志系统并不是很好用,而且侵入性非常高,我觉得我实现的日志系统(使用
strings.Repeat(rf.me)来区分不同 node 的日志)是个更简单、更好实现,也极大地帮助了我调试各种离谱问题的方案; - 在测试 Lab 3 的两个 speed test(其实我觉得这两个只测写请求的 speed test 非常地没有必要…)时请不要开启 race detector,否则几乎必挂;
- 如果你发现了莫名高频的锁争用(lock contention)问题,谨记在一个正常的系统里锁争用是非常罕见的情况,请首先检查你的几个常驻循环是否在无等待地无限获取锁(比如,
continue时跳过了time.Sleep),pprof 的火焰图(flame graph)对调试这一类问题通常很有帮助; - 当卡壳的时候,再读一遍课程的几个官方 guidance(尤其是 student guide)和 Lab 描述中的各种 hint;不要觉得参看如本文结尾列出的和本文本身(如我已经指出的那样,本文自愧远远不如分布式和存储领域的前辈们攥写的那些经验总结们优秀)这些总结是一件难以接受的事,诚然自己从零开始会更有成就感,但站在前人的肩膀上也一样有趣;
- 在实现 Lab 3 之前一定要先看课程的 Guest Lecture,Golang 的发明人 Russ Cox 在那个课上介绍了很多与 Lab 3 和 Lab 4 实现直接相关的并发 idiom),并且要注意检查你的实现有没有内存泄漏和协程泄漏的问题(我并不保证我的实现没有这些问题,因为我并没有仔细检查过…呜呜呜)。
现在,我将默认你已理解 Raft 算法的精髓,并已清楚如何在共识层上搭建真正的应用程序。
让我们开始吧。
全异步 shardkv
Lab 4B 无疑是难度最大的。相比有示例结构和明确参考的 Lab 2 raft,Lab 4B 要求大家从零开始设计分片的 KV 数据库,从头设计必须实现的分片移交(shard handoff)机制,没有任何示例和文字描述可做参考,还要保证这一机制不会违背线性一致性。
Lab 4 附有两个 challenges,分别要求我们实现失效数据的清除(Challenge 1)和异步变更配置的 shardkv(Challenge 2)。首先需要强调的一点是,如果你希望实现异步变更配置的 shardkv(也就是完成两个 challenges),一定要从设计的最初始就考虑这样做。
我们先来思考一下 challenge 2 到底是什么意思。Lab 4 中要求我们实现一个分片的分布式键值数据库,其核心是当配置变更(也就是从切片(shard)到组(replica group)的映射关系发生变化)时集群要同步反映这些变更:原先负责这个切片的组应不再负责这个切片,而新被分配这个切片的组应开始服务,并且要在和原组相同的数据上继续。在切片移交(handoff)的过程中不能接受客户端请求。
一个非常显然的实现就是同步的实现:我们编写一个新的常驻 goroutine,这个协程定期更新配置并计算变更(diff),如果发现变更,停止所有的客户端请求和整个 applier,移交切片并更新配置,待所有切片都就绪后才恢复客户端请求和 applier 循环。
这种简单的做法无疑效率低下。原因有二:首先,一个组会负责多个切片,而配置变更时需要移交和同步的切片通常只是一个组负责的多个切片的一部分。举一例:在配置变更 {1 [100 102 101 101 102 100]} -> {2 [100 100 100 101 101 101]} 中,组100负责从负责切片 [0 5] 变更至负责切片 [0 1 2],其中只需要同步 [5 1 2],而切片0在整个过程中都可以不中断服务,上述同步实现显然做不到这点;其次,一次变更可能需要来自不同组的多个切片,而一个切片可以在收到移交的数据时就立即开始服务,无需等待别的移交。还是上面的例子,变更配置时组100需要来自组102的切片1和组101的切片2,一旦收到来自组102的切片1,这一切片就能立刻开始服务。
所以,要完成 challenge 2,我们需要将配置更新、分片移交和分片恢复服务三个阶段完全异步化。当检测到配置更新时,仅仅停止需要同步的切片,不能阻塞客户端请求和 applier 循环;此后移交切片,并且在收到对应切片时立即恢复对该切片的服务。
已有的众多实现都采用了 “拉切片” 的同步方法(甚至连测试也暗示了这点… shardkv 的 TestConcurrent2 测试点上边的注释写的是 fetch shard contents…)。即当检测到配置变更时,由新被分配某个切片的组向它的「前辈」去 “要” 切片,相关的文章通常宣称这样的做法会更简单,尤其是在需要从宕机(crash)中恢复的若干场景下。
本文质疑这种说法。本实现证明了使用 “推切片” 的同步方法亦是可行的,两者间并无显著的复杂度区别,无论是就 RPC 次数还是宕机恢复逻辑的复杂程度而言。本节余下部分谈论的「问题场景」对 “拉切片” 依然适用,且要在那种同步方法中解决所有这些问题很可能需要相似的机制。鉴于两者并无显著的复杂度差异,各位读者可任意地自由选择同步方法。
分片异步移交(async handoff)协议
需要强调的是,shardkv with challenges 的要点是江配置更新、分片移交和分片恢复服务这三个部分完全解耦并使之异步化。任何实现方案都要做到这些,而此处给出的方案只是若干可行解中的一种。
在 Lab 4A 中我们已经实现了负责提供一致 Config 的 shardctler,而 Lab 4B 的 shardkv 泽通过 shardctler.Clerk 与其定期通信并拉取配置。注意到从配置更新到分片恢复服务之间有若干阶段,每个阶段间都有可能发生宕机和换主,请确保你的实现能够处理各种情形(在下文「问题场景」和「解决方法」将更多地涉及具体的错误场景),这首先要求每个节点对当前配置和「更新步骤进行到哪个阶段」要有一致的认识。
因此,整个 reconfiguration 过程的大部分逻辑应在 applier 循环中实现。对于一轮 reconfiguration,集群异步地按三个步骤工作,并依赖 Raft 层实现状态的一致转移:
- 更新配置:首先 Leader 会定期拉取配置。当发现配置的
Num比本地配置更大且所有分片的状态都是正常状态时,调用 Raft 层Start。对应示意图中DoUpdateConfig。 - 更新配置:接下来由包括 Leader 在内的每个节点的 applier 循环接收自 Raft 层推送的最新配置,由这个最新配置更新当前配置、计算 diff 并据此更新每个分片的状态(这个接下来还会讲到),同时开始分片移交(handoff)。对应示意图中
applyConfig(这是一个由 applier 循环根据消息类型调用的方法)。 - 移交分片:接收到移交(handoff)消息的组的 Leader 调用
Start,成功后向原组发送移交成功消息。对应图中Handoff。 - 移交分片:每一个节点的 applier 循环接收移交消息并对应更新自己的 kv map。对应图中第一个
applyMsg。 - 分片恢复服务:当原组的 Leader 收到分片移交成功消息后,调用 Raft 层的
Start。对应图中HandoffDone。 - 分片恢复服务:包括 Leader 在内的每个节点的 applier 循环接收自 Raft 层推送的配置更新完成消息,清理对应的 key(Lab 4 Challenge 1)并将这些切片恢复到正常状态,为下一轮 reconfiguration 做准备。对应图中第二个
applyMsg。
示意图如下:(我知道我的字很丑,请别喷我… 呜呜呜呜 🥺🥺🥺)

注意到在一次 reconfiguration 的流程全部完成之前不会更新下一个配置,因为在最后一步恢复分片状态前一定有分片的状态不是正常状态,而当有分片是非正常状态时步骤1不会启动。
可以看到整个 reconfiguration 过程还是比较复杂的,并且有若干细节问题需要仔细考虑,这会在下文中详述。由于本节只对总体设计做概观式的鸟瞰,以下仅再简要讨论三个问题:
问题1:分片状态
第一个问题是,上文不断提到分片除了 Config 中给出的 shard -> gid 对应关系外,还有一个额外的「状态」需要维护。分片有哪些状态?应该如何管理这些状态?
当一个组的节点接收到 Raft 层推送的最新配置时,要计算 diff 并更新分片状态(第2步),对于一轮 reconfiguration,切片移交的发送方和接收方都会这么做,从而产生两种可能:一个分片从别处移给我,一个分片从我这交给别处。算上正常状态,一共有三种状态:Serving、Pulling 和 Pushing。注意到在这三种状态下都是不能提供服务的。
另外是如何管理这些状态。一种方案是约定特殊的 Config.Shards 值,比如 -1 表示 Pushing、-2 表示 Pulling,这样做可能会给 diff 算法引入额外的复杂度,并且更新 Config.Num 的策略(是当所有特殊值都消除时才更新 Num 吗?)还会引入别的问题。更好的方案是在 Config 之外维护一个额外的 ShardState 数组,并通过 Golang 的常量枚举语法提升代码的可读性:
1 | type ShardKV struct { |
问题2:RPC 消息类型和 RPC handler 的个数
在上文的步骤描述中,出现了两个 RPC handler 和两对共四种 RPC 消息:用于移交分片的 HandoffArgs 和 HandoffReply,以及用于完成分片移交的 HandoffDoneArgs 和 HandoffDoneReply。
你可能会觉得,一个 RPC handler 可以既处理发出去的请求又处理回来的回复,所以只用一个 RPC handler 和一对 RPC 消息 func Handoff(args *HandoffArgs, reply *HandoffReply) 就能解决问题。这样做是行不通的。具体原因请见下文「问题场景」一节。
问题3:持久化
最后一个问题是哪些状态应该被持久化。如上所述,从配置更新到分片恢复服务之间有若干阶段,每个阶段间都有可能发生宕机和换主,所以请务必仔细考虑有关持久化的问题,在本部分的剩余几节会更加详细地讨论之。
对 reconfiguration 的整个流程的鸟瞰式概括就到此结束了。如果你还没有开始动手完成 Lab 4B,为达到最好的学习效果,你应关掉本文,开始自行编写实现,并仅当遇到难以解决的问题时(确保你已经足够努力地 debug)继续阅读本文的剩余部分。
问题场景
在设计并实现(主要是设计)上面的流程中遇到了若干问题,其中有一些问题的解决方法并没有详细包含在上述流程中,主要是因为显然由读者自行发现这些问题并自行思考解决的机制将更加有益。本节将总结我在设计和过程中遭遇的若干会引起问题的场景,需要注意这并不一定覆盖了所有可能的问题场景,而仅仅是我遇到的。在本文的余下部分,称一次移交的发送方为 “源组”,接收方为 “目标组”。
第一类是与分片移交机制本身相关的场景,共有四种:
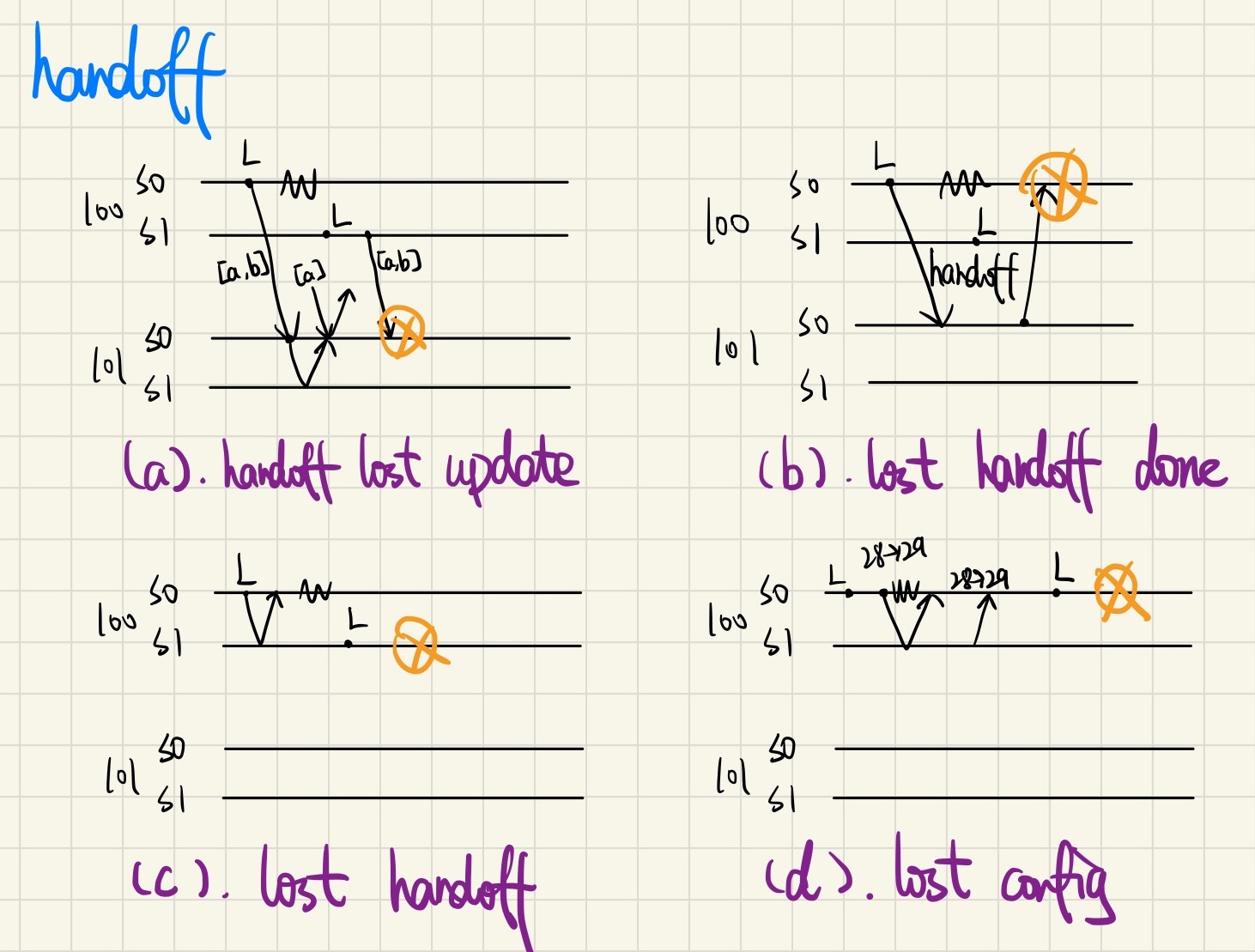
a. handoff lost update
组100发起移交,随后该节点宕机(Z字型线表示节点宕机)。接收组完成了更新并开始服务请求,而源组的新 Leader 又发起了一次移交,接收组应用已经应用过的移交,造成状态回退。
b. lost handoff done
组100发起移交,随后该节点宕机。接收组完成更新并返回移交成功消息,由于源组的原发送节点已经宕机,导致它无法向 Raft 层提交移交完成的消息,造成
思索死锁。c. lost handoff
组100的原 Leader S0 通过步骤1和步骤2在组内更新完配置,正准备发起移交时宕机了,新选出来的 Leader S1 以为原 Leader 已经发送了移交,于是一直等待移交完成消息,造成死锁。
d. lost config
组100的 Leader S0 完成了步骤1并在步骤2前恰好宕机,而 S0 恢复后一开始不是 Leader,从 Raft 层传来的
Config不会触发移交,从而丢失了一次 reconfiguration。
还有一类场景是与消息去重相关的,但这与去重机制的具体实现相关,在此不再赘述。
解决方法
解决问题场景
a. handoff lost update
或许简单的去重就能解决这个问题,然而这必须在同一个组的每个节点都使用相同的
ClientId时才行得通。我并没有使用这种方法(或许这样做会更简单,欢迎尝试了这种方法的读者在评论区指出其优劣)。我的解决方法是在应用状态前增加两下检查:首先检查在移交的分片对应本地状态中,是不是有Pulling状态的分片,如果没有则明显说明这是一个重复的移交。然而这样做并不足够,因为在目标组收到重复移交之前可能已经进行了下一轮 reconfiguration,所以还需要检查HandoffArgs.Num是否是最新的。b. lost handoff done
这就是在问题2中提到的不能使用一对 RPC 消息和一个 RPC handler 就搞定移交的原因。这里的问题本质上是当一个节点需要对某个 RPC 的回复达成共识时,回复可能被网络延迟太久以至于到达时该节点已不再是 Leader,无法调用
Start。设计复杂的 RPC 协议并不能解决这个问题而只是延后了问题。解决方法其实很简单,上文也已提到:使用多一对 RPC 消息和多一个 RPC handler 来传递「完成操作」的信息,并且信息的发送方要轮询接收方直至成功发送(「完成操作」消息的接收方也就是「操作」消息的发送方)。注意,在配置更新后,「操作」消息发送方的地址可能会被丢失。另外一点是所有依赖 RPC 回复的
Start调用都会出现这个问题,你的实现可能以别的形式(而不是情形b)引入了它。c. lost handoff
该场景有显然的解决方法,在此概不赘述。
d. lost config
这是一个有点意思的场景,应该有多种解决方法。我的方法是在步骤1传入 Raft 层的
shardctler.Config之外额外包一层,一并传入「是哪个节点提交的这个shardctler.Config」,当收到 Raft 层推送的配置时,如果这个值和本节点的编号匹配,则无视本节点可能不是 Leader,立即发起移交:shardkv/server.go 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41type Config struct {
Conf shardctrler.Config
Committer int
}
func (kv *ShardKV) DoUpdateConfig() {
updateConfig:
for {
time.Sleep(UpdateConfigInterval)
if !kv.isLeader() { continue }
for _, state := range kv.shardStates {
if state != Serving {
kv.mu.Unlock()
continue updateConfig
}
}
num := kv.config.Conf.Num + 1
kv.mu.Unlock()
kv.rf.Start(Config{kv.mck.Query(num), kv.me})
}
}
func (kv *ShardKV) applyConfig(latest Config, commandIndex int) {
if commandIndex <= kv.lastApplied {
return
}
// ...
kv.updateShardStates()
}
func (kv *ShardKV) updateShardStates() {
latest := kv.config
handoff := make(map[int][]int) // gid -> shards
for shard, gid := range kv.lastConfig.Conf.Shards {
// ... calculate diff
}
if kv.isLeader() || kv.me == latest.Committer {
kv.handoff(handoff, latest.Conf, kv.copyDedup())
}
}
去重
如何去重和如何移交去重表会带来很多问题,但是只要你使用了合适的去重方案,这一切都会变得十分简单。我推荐的方案是使用 SequeceNum 对消息进行去重(客户端的每个请求都要带 ClientId 和递增的 SequenceNum,且仅在服务器返回 OK 时递增 SequenceNum),这会使得解决各种与去重(和移交去重表)相关的问题变得非常容易。我一开始是用随机而非递增的 RequestId 进行去重,导致用于消息去重的数据结构比较复杂,遇到了很多问题,移交去重表的流程也很麻烦。
另外一个有关去重的细微问题是如果使用 SequenceNum 机制去重请求,那么客户端必须只有一个 goroutine 访问 SequenceNum 这个状态(不能存在并发)。如果是 Clerk 这很容易做到,但是对于移交分片的服务器到服务器通信则需要额外的机制。我使用了一个 handoffCh 通道和的一个常驻的 goroutine 协程来保证这点,这应该还算是一个不错的结构:
1 | func (kv *ShardKV) DoPollHandoff() { |
思考一下
handoffCh应该是 buffered 还是 unbuffered channel?如果是 buffered channel,那么它应该有多大?
代码结构
本节将简要介绍本实现的代码结构。毫无疑问将这整个可以说是相当复杂的分片移交协议实现得简洁、清晰、易于维护,并不是一件轻松的事。
本节描述的代码结构可参看分片异步移交协议一节中的示意图。
由于无论是 shardkv 还是 Raft 协议本质上都是一个巨大的事件循环(event loop),所以使用常驻 goroutine 中的无限循环对各种事件进行响应就自然成为了一个合适的方案。启动时,StartServer 会启动三个常驻 goroutine:
DoApply:Raft 层 apply log 事件循环,监听applyCh。DoUpdateConfig:仅 Leader 有效,不断轮询 shardctler 并将最新Config推入 Raft 层。DoPollHandoff:如上所述,使用SequenceNum进行去重时需要保证只有一个 goroutine 会访问SequenceNum状态,这就是那个 goroutine。它监听handoffCh,发送请求并递增kv.num。
在分片异步移交协议一节中,我们介绍了本全异步 shardkv 实现使用的「基于推操作」的分片移交协议,以及该协议需要哪些 RPC handler。RPC handler 共有两个:
1 | func (kv *ShardKV) Handoff(args *HandoffArgs, reply *HandoffReply) { |
startAndWait 是一个所有的 RPC handler 都要调用的方法:它调用 raft.Start,然后阻塞,直到 DoApply 循环通过 doneCh 通知该操作已完成时再返回:
1 | type Done chan GetReply |
如步骤1所述,常驻 goroutine DoUpdateConfig 在条件适宜时将最新的 Config 推送至 Raft 层,一切顺利的话这个最新的 Config 将从 raft.applyCh 中推送至 shardkv 的 DoApply 事件循环。DoApply 中包含了整个 shardkv 的绝大部分处理逻辑:
1 | func (kv *ShardKV) DoApply() { |
DoApply 在收到一条 Raft 层推送的消息后,首先判断消息类型。如果是 Config,通过 applyConfig 应用状态变更并执行步骤2;如果是一般请求(Get 和 PutAppend)和分片移交消息,则通过 applyMsg 方法应用状态变更并执行协议的步骤3(对于 HandoffArgs)或步骤6(对于 HandoffDoneArgs)。当这一切完成后,通过 kv.done 结束对应 RPC handler 阻塞并返回。
applyConfig 方法则严格执行了步骤2,在上文已经给出过这段代码的脉络了。注意到实现需要正确处理场景d,且对于一些实现而言要如何优雅地(最大代码复用)解决场景c也需要一些思考。该方法末尾调用的 handoff 方法将当前消息推送到 handoffCh 中,由于在去重一节中描述的问题,我们需要使用常驻 goruotine DoPollHandoff 轮询目标组并发送分片移交消息,该方法的代码结构已在上文中给出过了。
而 applyMsg,如你猜测的那样,这个方法 is nothing but a giant switch:
1 | func (kv *ShardKV) applyMsg(v raft.ApplyMsg) (string, Err) { |
在代码中有两处省略的 // ... do some check,需要仔细考虑应该进行哪些检查、返回哪些错误。注意返回的不同错误 ErrWrongLeader、ErrWrongGroup 和 ErrTimeout 会导致客户端的不同行为。请谨慎思考在什么情况下返回哪种错误才能既不违反协议又不引入死锁。
LeaseRead with noop
在写这篇文章时我总觉得读者们早已熟悉本文的第一部分,而这一部分可能才是大部分读者关注的主题(只是一个猜测)。在那篇大名鼎鼎的 [Ongaro 2013] 论文(也就是课程给定的那篇论文)的第八节 8. Client Intersection,Ousterhout 教授(此人还是 A Philosophy of Software Design 这本很棒的书的作者,同名的 Talks at Google 讲演也非常棒)提了这么一段话:
Read-only operations can be handled without writing anything into the log. However, with no additional measures, this would run the risk of returning stale data, since the leader responding to the request might have been superseded by a newer leader of which it is unaware. Linearizable reads must not return stale data, and Raft needs two extra precautions to guarantee this without using the log. First, a leader must have the latest information on which entries are committed. The Leader Completeness Property guarantees that a leader has all committed entries, but at the start of its term, it may not know which those are. To find out, it needs to commit an entry from its term. Raft handles this by having each leader commit a blank no-op entry into the log at the start of its term. Second, a leader must check whether it has been deposed before processing a read-only request (its information may be stale if a more recent leader has been elected). Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests. Alternatively, the leader could rely on the heartbeat mechanism to provide a form of lease [9], but this would rely on timing for safety (it assumes bounded clock skew).
寥寥几笔便道尽了本部分的主角。首先,正如论文作者在第一节 1. Introduction 指出的那样,Raft 协议的一大特点就在于该协议是被切分成了几个独立(在研究和实现的双重意义上)的部分,而每一部分都有诸多实现方法和优化。这些优化大多关注我们经常用「性能」一词模糊地一言以蔽之的两个不同方面:其一是可用性(availability,或 liveness),比如改善在网络不稳定下的选举过程的 PreVote 算法;其二是吞吐量(throughput),它关注对于不同请求类型,如何提高集群对它们的处理能力——比如本部分将要涉及的 LeaseRead,就是如此。
优化只读请求(read-only)
据我在这一领域十分粗且一知半解的了解,对 Raft 协议的只读请求的实现方法,主要有以下几种:
LogRead,没有任何优化,每一个 Get 请求都要由 Leader 发起、在整个集群内部达成共识,这也就是课程 Lab 要求的实现方式。
ReadIndex,基本思路是在收到只读请求时首先记录当前
commitIndex为readIndex,然后发起一轮心跳确认自己还是 Leader,最后等待本地lastApplied > readIndex并返回结果。这种方法由 Leader 直接在本地服务只读请求,不需写日志,但仍然需要一轮心跳。注意,仅在一些情况下才需要记录 + 等待的额外步骤。若无需等待,则任何一个只读请求都能在访存后直接返回,无需与共识层交互,并且具有所谓 wait-free 的良好性质,关于这个问题的更多内容请见下文。
LeaseRead,这就是论文中简要提及的优化,也即本部分的主角。实装此优化时,每个 Leader 在每一轮心跳获得多数
Success: true后则获得一个租约(lease),过期时间是发起这轮心跳的开始时间(思考一下,为什么?)加上一个固定值(LeaseDuration)。需要保证在本 Leader 的租约过期前不会换主(LeaseDuration < ElectionTimeout),同时在租约过期后本 Leader 不应继续服务。FollowerRead,广义的字面含义指一切使读请求能由 Follower 响应的优化,即 QuorumRead(很快就会讲到)是 FollowerRead 中的一种。在这里我采用了 TiDB 文档(这也是这个词的最常见语境)中对 FollowerRead 的狭义定义:Follower 在响应读请求前需要先向 Leader 询问他的
commitIndex,然后在本地等待lastApplied >= readIndex,这本质上和 ReadIndex 并无太大差别。注意在这个过程中虽然号称 “FollowerRead” 但其实仍需 Leader 的参与;虽然依赖的程度有所降低,但和上述几种优化一样,读请求同样单点地依赖 Leader,导致读请求的可扩展性(scalability)依然受限。有一种对 FollowerRead 的进一步改进是向除 Leader 外的多数节点询问
commitIndex,这样是否可以避开 Leader 服务读请求呢?答案是否定的。原因其实很简单,我将这点留给读者思考,欢迎在评论区给出你的答案 :-)。为了进一步提高集群的可扩展性,[Arora 2017] 中提出了 QuorumRead(在论文中称作 Strongly Consistent Quorum Reads),可使读请求完全由 Leader 之外的节点响应,从而彻底解决了对 Leader 的单点依赖。但这一方法对底层的数据模型提出了限制,它要求每个数据都必须附带版本号或时间戳(timestamp),虽然在很大一部分 Raft 共识算法的应用场景下(如 MVCC)这点是成立的,但 MIT 6.824 Lab 并不属于其中之一,且本节仅讨论较通用的优化方法,故在此不作讨论。
如果要做一个非常华为的对比图,这四种算法分别就是:
| 只读(read-only)请求服务算法 | 能由 Follower 响应? | 无需心跳? | 无需写日志? |
|---|---|---|---|
| LogRead | 😐 | 😐 | 😐 |
| ReadIndex | 😐 | 😐 | 😃 |
| LeaseRead | 😐 | 😃 | 😃 |
| FollowerRead | 😃 | 😃 | 😃 |
当然,上边的对比还不完全华为的一点缺陷就是,该表格反映了真实情况(
注意到,上面的四种算法需要提供的核心保证只是,Leader 在服务某个只读请求时还是 Leader。无论何种优化都只是以更有效率的方式提供这条保证,否则在网络分区的场景下就会违背线性一致性。
还有一点需要注意的是,相比 ReadIndex 而言,LeaseRead 引入了对时钟偏斜(time skew)的依赖,这要求集群内的各个节点的时钟必须以近似的速率滴答。由于这个额外的限制,etcd 的共识层默认是基于 ReadIndex 算法的(ReadOnlySafe),但提供了一个选项可供用户切换至 LeaseRead 算法(ReadOnlyLeaseBased);但 TiKV 却是默认实现的 LeaseRead 甚至是 FollowerRead,总的来说这需要具体问题具体分析。
wait-free 读
另外一点问题是,网上对于 ReadIndex 的描述大多都提到了「记录当前 commitIndex 为 readIndex,随后等待本地的 lastApplied >= readIndex 时才能查询并返回请求」(见 [Ongaro 2014])这一额外的「延迟查询」步骤,但却鲜有文字介绍这一步骤的原因和必要性。
小专栏:non-blocking 和 wait-free
non-blocking 和 wait-free 是两个用于描述「无需等待」这一良好性质的常见概念。注意它们之间的区别:前者指对于一组并发的访问,其中有至少一个能在有限步内完成;而后者指这组并发访问中的每一个都能在有限步内完成,显然后者是一个更好、也更难达到的性质。另一个词 lock-free 经常被视作是 non-blocking 的同义词,这是不够准确的,一个算法没有使用互斥锁并不代表它就能保证至少一个进程能在有限步内完成。比如直接使用 CAS 实现的并发访问(这满足一般理解中「lock-free 无锁」的含义)如果没有随机化 backoff 时间,仍然可能出现永久等待的情况。更加详细的描述参见 [Valois 1994]。
注意到一个实现是 wait-free 的并不意味着它就一定比 non-blocking 的实现在算法意义上更优。有可能仅仅是它的一致性性质更弱,或暴露的接口更低级,这有点类似 Chubby 和 ZooKeeper 之间的关系([Hunt 2010])。
对于 FollowerRead,如果 Follower 在处理只读请求前不询问并等待当前 Leader 的 commitIndex,那么显然会破坏线性一致性。因为即便一条日志已经被提交,由于提交是异步的(提交仅仅说明前移了 commitIndex,但是要等这些条目都应用到状态机中,还要等 applier 循环异步地逐个递增本地 lastApplied,直到 lastApplied >= commitIndex),可能出现一个条目 Follower 先应用而 Leader 后应用的情况,所以具有 wait-free 性质的 FollowerRead 实现不满足线性一致性。
而对于 ReadIndex 和 LeaseRead 优化,如果读和写请求都由 Leader 处理,并且一个写请求直到被应用到状态机(apply)后才会回复,那么去掉等待步骤仍然满足线性一致性,且具有只读 wait-free 的良好性质。因为一个写请求在应用后才会返回,那么之后的读请求一定可以(如果你的锁协议没有炸掉的话)读到最新的写,而并行的写和读无论是否读取到和它并行的写的结果都是满足线性一致性的。所以只要读和写都由 Leader 处理、且写仅在 apply 后才予以回复,那么 ReadIndex 和 LeaseRead 优化的 wait-free 实现都满足线性一致性。
有些读者可能会疑惑为何 ReadIndex 和 LeaseRead 的 wait-free 实现无需担心 Follower 和 Leader 的 applier 循环间不同步的问题(这个问题导致 wait-free 的 FollowerRead 不满足线性一致性)。原因是在 ReadIndex 和 LeaseRead 优化中读写都是由当前的有效 Leader 处理的,而新 Leader 上任时会提交 noop 从而保证新 Leader 的 lastApplied 至少和老 Leader 的一样大。
本实现是只读请求 wait-free(访存后直接返回)的 LeaseRead 优化。
注意到这里其实还有若干细节问题没有讨论,在下文中将逐一涉及。
LeaseRead with noop
和很多文章描述的情形不同,实现这一优化的工程量并没有很大,事实上大部分修改都紧凑而有条理。引入 LeaseRead with noop 需要引入两个部分,首先是 LeaseRead,其次是 noop。(怎么感觉这话就很有搁这搁这那味。。。)
引入租约机制并不复杂,主要的修改只有寥寥数行:
1 | diff --git a/src/raft/raft.go b/src/raft/raft.go |
lease 是在一轮心跳发起时生成的,此外需要避免租约的到期时间发生回退。
noop 的引入则要更有意思一些。由于课程的测试套件要求日志的 Index 是密集的,而提交的 noop 会破坏这点。我的方法是引入一个新的 Seq 参数,当 DoApply 循环推送日志给上层服务时将 Seq “假装”成 Index,但仅当处理请求(而非 noop)时 Seq 才会递增,满足 Seq < Index。
这一方案乍看起来没有什么问题,但当需要 Snapshot 时就会犯难。
由于当接收到 InstallSnapshot 时需要设置 log[0] 的 Seq 值,所以要实现 noop 需要变更 CondInstallSnapshot 对外暴露的方法签名,也就意味着需要对测试套件做一点小小的修改。好在课程的测试套件编写得相当清晰,只需两行修改就能达成目标:
1 | diff --git a/src/raft/config.go b/src/raft/config.go |
我已经听到读者大佬们当发现原来还要改测试套件时不屑的嘘声了(
问题场景 & 解决方法
即便已给出了算法概览,要真正实现并通过测试还是会遇到若干问题。本节将简要列举这些问题并给出我的解决方法。
第一点需要注意的是,一个 Leader 在上任前会提交一个 noop,这可能会导致此前还未提交的条目被提交并应用。在这一过程中不能服务任何请求(包括只读请求),因为这中间的状态不能被外界观察到。我们可以通过引入一个额外的 leaseSyncing 状态并修改 GetState 的语义来实现这点限制:isleader = rf.state == Leader && !rf.leaseSyncing && time.Now().Before(rf.leaseEndAt)。leaseSyncing 在节点转为 Leader 并提交 noop 时置为 true,并仅当 commitIndex >= lastApplied 才关闭 leaseSyncing。
这里还有一点细节:并不是只有 applier 循环才会递增 lastApplied。你需要检查代码中各处对 lastApplied 的修改是否需要检查并关闭 leaseSyncing,漏掉一个就有可能导致 GetState 一直返回 ErrNotLeader 而引起死锁。
第二点问题是,由于我实现的 LeaseRead 改变了 GetState 和 needApply 的语义,这有可能引入另外的死锁问题。比如, applier 循环应该提供的保证是只要一个请求被提交,那么它最终就一定会被应用;如果你的 needApply 考虑了租约,那么可能出现一个条目在 Start 时租约有效、但之后由于租约过期、又没有新的写请求而一直无法被应用的情形,从而导致死锁。总的原则是你需要保证在 GetState 返回 true 时提交的请求最终也一定会被应用。注意到由于一个有效的 Leader 会不断续期租约,所以通常这只需要更频繁地检查 applier 循环的触发条件就能解决。
结语
身处一个氛围并不太好——真正的双非学校,大家都在卷考研 / 卷大厂,没有人关心技术本身以及这些「没什么用」的知识——的环境,很多时候我们只有自己。我曾多次想与人讨论自己从文献中冥思苦想得来的 eureka 而无人回应,也感到自己在技术上的存在一直是靠网络维持。不过,或许还是有少数人同行,而能在现实中认识思想开明的朋友是一件十分幸运的事:感谢室友们在我激动兴奋之时的耐心倾听(有时还会回应,不得不说其中很多想法颇有见地),尽管他们对我的话题并无太大兴趣,但却真切反映了许多值得欣赏的品质。
所以对于在同学间(尤其是学弟学妹间)时常爆发的有关我们这双非和他们那双非孰优孰劣(通常还伴随着自己来了这里是不是亏了)的讨论,我通常不屑一顾。要真论教学(其实很有可能主要的限制因素反而是学生的水准),只要没有达到 211 和 985 的级别大概都难分高下,而在这种情形下只能祈望学校管理宽松:如果你难以提供高质量的教学,至少不要阻止学生们另寻出路。
好在一般的双非都会提供至少是舒心的环境。不断电不断网不停水(冷水也不收钱),不查寝室不管纪律不常查课,实验室摆满高端的硬件设备尽管连老师也不会用却也从不阻止感兴趣的学生借来私下捣鼓,学校还是提供了足够宽容的环境,充分理解各人都应有各自的独立的想法。
刚来这所无疑是令人失望的学校时我也自怨自艾,然而很多时候学历并不是仅靠我们的才智就能充分决定的事,这和地区以及家庭等一系列被称为「平台」因素息息相关。有一些彻夜难眠的夜晚你可能会觉得自己并没有比更高学历的同学们笨多少,你也未必就一定无法达成他们的技术成就(也就是说他们仍在你的「视线之内」);而究其原因,与其说是你真的不配拥有更加光彩夺目的生命,不如说仅仅是你没有足够高的「平台」。一个人要达到卓越首先必须相信自己是卓越的(米沃什语),要成为这样的环境中的佼佼者必须向更高更远处看齐,比如完成一门公认为较有挑战的课程。
一想到我大一时也是十分痛苦就会觉得正是近些年来明白的许多道理才使我更加平静和坚定。一点双非学子的肺腑之言,与诸位共勉。
参考文献
- [Ongaro 2013]: Ongaro, Diego, and John Ousterhout. “In search of an understandable consensus algorithm (extended version).” (2013).
- [Ongaro 2014]: Ongaro, Diego. Consensus: Bridging theory and practice. Stanford University, 2014.
- [Valois 1994]: Valois, John D. “Implementing lock-free queues.” Proceedings of the seventh international conference on Parallel and Distributed Computing Systems. 1994.
- [Hunt 2010]: Hunt, Patrick, et al. “{ZooKeeper}: Wait-free Coordination for Internet-scale Systems.” 2010 USENIX Annual Technical Conference (USENIX ATC 10). 2010.
- [Arora 2017]: V. Arora et al., “Leader or Majority: Why have one when you can have both? Improving Read Scalability in Raft-like consensus protocols,” in 9th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 17), Santa Clara, CA, Jul. 2017. [Online]. Available: https://www.usenix.org/conference/hotcloud17/program/presentation/arora
另请参阅
特别推荐的资料以粗体标注。
- https://github.com/OneSizeFitsQuorum/MIT6.824-2021
- 2021 MIT 6.824 札记 - https://www.inlighting.org/archives/mit-6.824-notes/
- 一致性模型与共识算法 | 谭新宇 - https://zhuanlan.zhihu.com/p/463140808
- 线性一致性和 Raft | PingCAP - https://pingcap.com/zh/blog/linearizability-and-raft
- TiDB 新特性漫谈:从 Follower Read 说起 | TiDB Robot - https://zhuanlan.zhihu.com/p/78164196
- Raft ReadIndex 有什么神奇之处? | 吴祖洋 - https://www.ideawu.net/blog/archives/1192.html
- TiKV 功能介绍 - Raft 的优化 | PingCAP - https://pingcap.com/zh/blog/optimizing-raft-in-tikv
我靠,又是一万多字,真是写死我了。
深入 MIT 6.824:实现 LeaseRead 和全异步 shardkv

